Các sản phẩm
Web,
App (các nền tảng như PHP,
React, React Native), một số dự án
AI (thực hiện trong môn Nhập môn AI)
Link published: https://github.com/MauDucKG
Hiện thực một ứng dụng web sử dụng PHP và cơ sở dữ liệu MySQL dugnf để giới thiệu về một doanh nghiệp bán hàng (tên là BigFarm) cùng với team Lemon trong môn Lập trình Web tại trường đại học.
Có các tính năng như:
- Đăng nhập
-
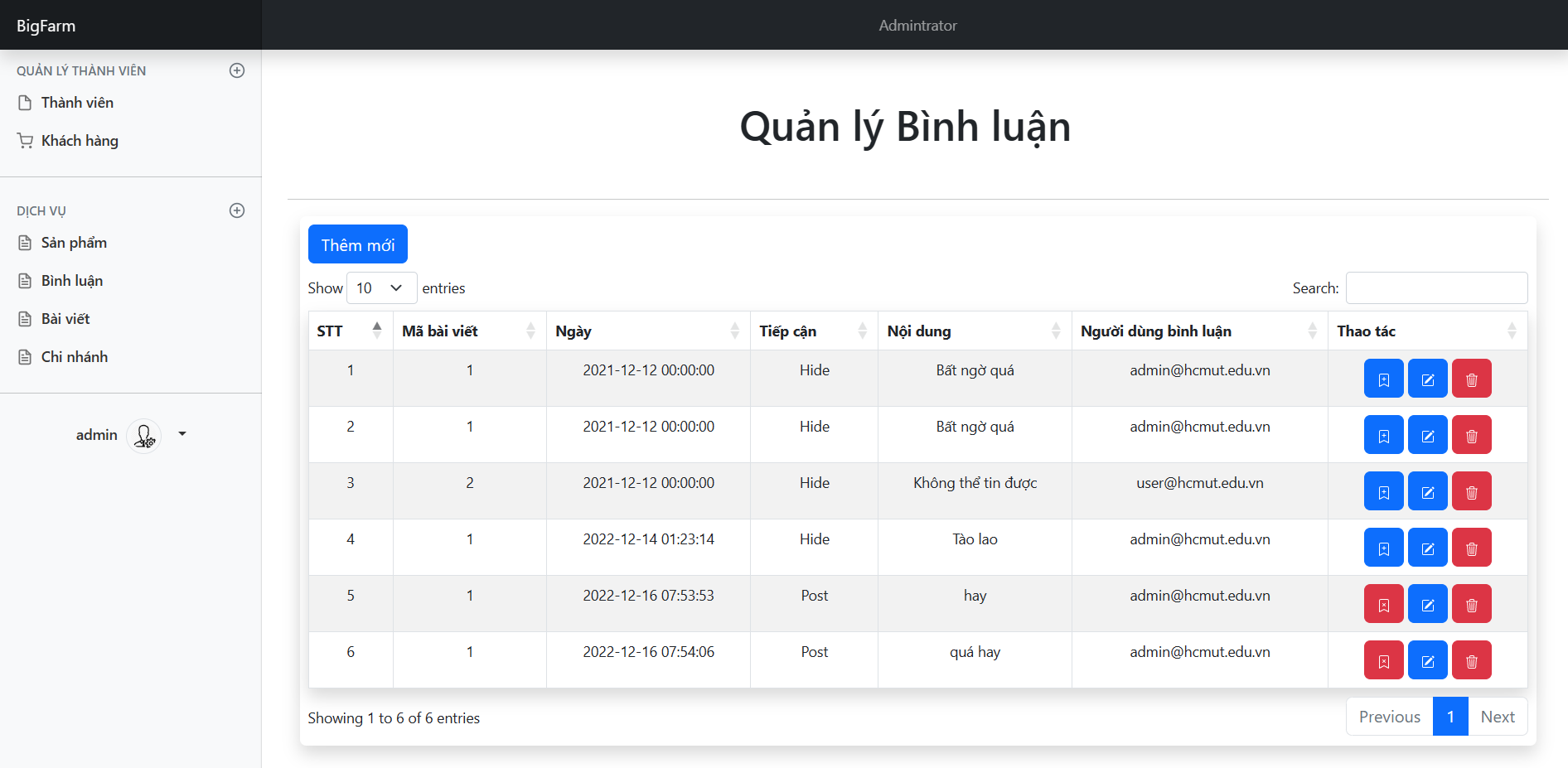
Quản lí người dùng, admin
(thêm, xóa, sửa) -
Quản lí các sản phẩm
(thêm, xóa, sửa) -
Quản lí các bài viết, chi nhánh
(thêm, xóa, sửa) - Phân trang trên một số màn hình
- Có sử dụng
Bootstrap 5cho ứng dụng - Sử dụng cơ sở dữ liệu
MySQL - Published trên một domain
Các chức năng được nhóm Lemon hiện thực theo mô hình
MVC để đảm báo tính toàn diện của một dự án
trên mọi mặt, là thành quả của team với khoảng
150 commit trong khoảng thời gian tầm 2
tháng. Có thể tham khảo chi tiết quá trình thông qua những
link sau:
Link hiện thực: https://github.com/MauDucKG/BigFarm
Link published: http://bigfarm.ezyro.com

Hiện thực một ứng dụng điện thoại cập nhật số ca mắc Covid-19
Cập nhật số ca mắc
Covid-19, số ca mắc mới trong ngày, thời
gian cập nhật gần nhất, số trường hợp tử vong ở
- Trên toàn thế giới
- Ở từng nước
- Ở từng tỉnh của Việt Nam
Sử dụng Flutter là ngôn ngữ lập trình.
Dữ liệu được xuất ra sử dụng API để kéo về
(phần Global và Country) và Parse HTML để kéo dữ liệu ở
phần Vietnam.
Link hiện thực: https://github.com/MauDucKG/ltnc_hk212
Trong công ty có nhiều phòng ban, vị trí chỗ ngồi (seat) nhóm Coffein thực hiện project này với mong muốn quản lí những chỗ người cũng như nhân sự này dễ dàng hơn. Dự án được thực hiện trong thời gian thực tập tại công ty Cybozu Việt Nam cùng với team Coffein cùng 2 mentor là anh Viễn và chị Huyền
-
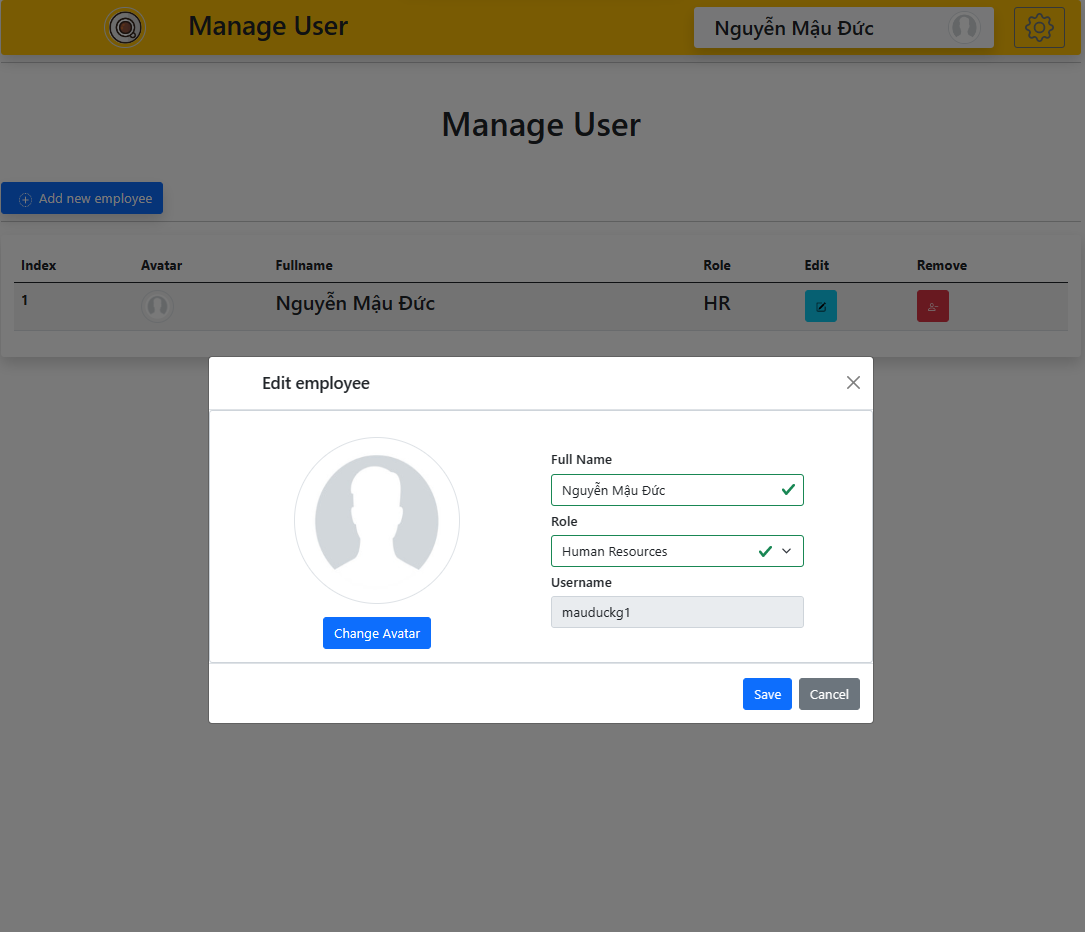
Đăng nhập (có áp dụng cơ chế
Authen,AuthorbằngAcess TokenvàRefresh Token) kết hợp vớiHash password - Quản lí nhân sự với các chức năng cơ bản như thế xóa sửa
-
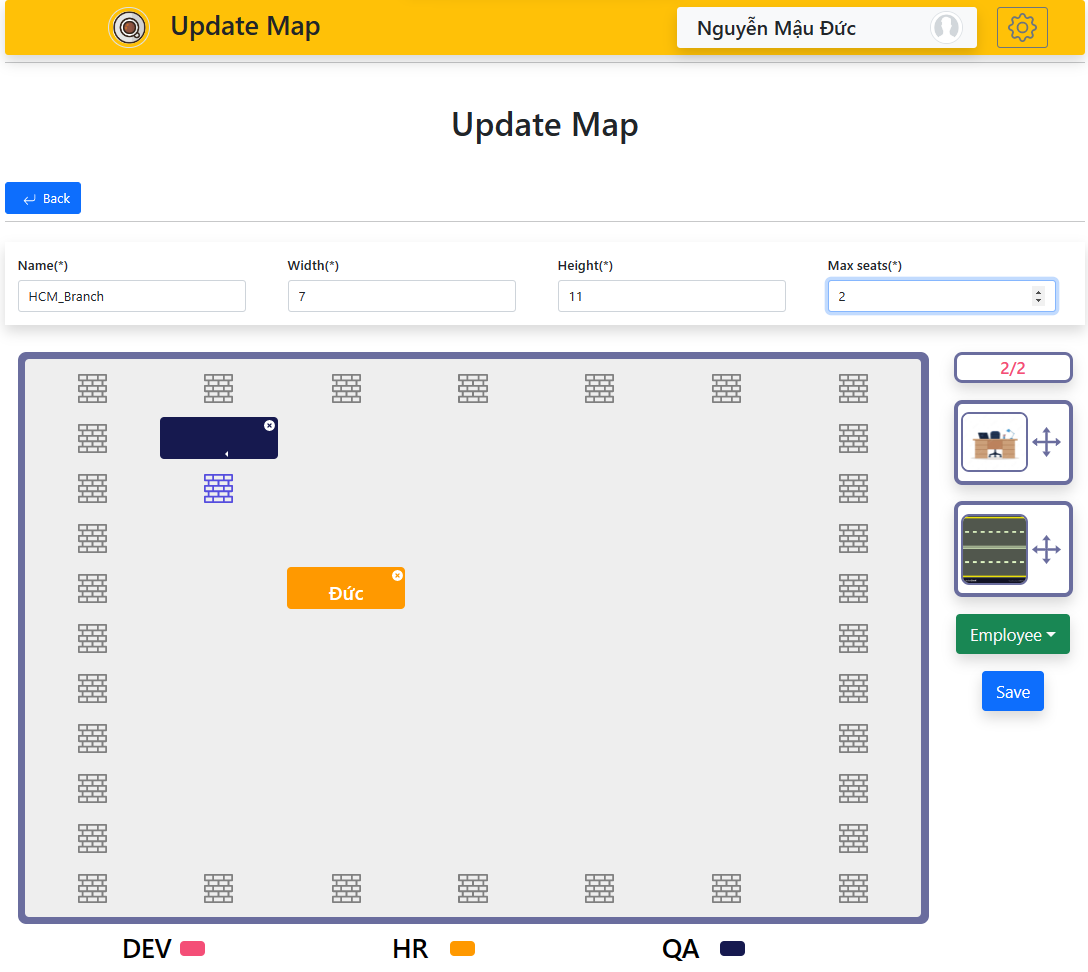
Quản lí map (quản lí vị trí các chỗ ngồi) ở đây sử dụng
thư viện
react-grid-layoutvàreact-grid-systemđể quản lí chỉnh sửa. - Quá trình làm việc theo mô hình Scrum trong lập trình dự án phần mềm
- Published
Link spec: https://github.com/cvn-intern/Coffeein-Seatmap/wiki

Tạo ra một Website đơn giản để lưu những thông tin căn bản cho bản thân.
Sử dụng Bootstrap 5 để tạo giao diện đẹp và
nhanh chóng
Hỗ trợ nghiên cứu về chủ đề: Cải thiện
công nghệ Nhận dạng Giọng nói Tự động (ASR) cho
các Ngôn ngữ nghèo tài nguyên (dữ liệu) thông qua Tăng cường
Dữ liệu. Nghiên cứu này tập trung vào việc tăng cường dữ
liệu để cải thiện hiệu suất của công nghệ Nhận dạng Giọng
nói Tự động cho các ngôn ngữ thấp tài nguyên. Phương pháp
này được đề xuất nhằm tối ưu hóa quá trình huấn luyện mô
hình và tăng cường khả năng phân loại giọng nói của ngôn ngữ
đó. Kết quả nghiên cứu này có thể giúp cải thiện hiệu suất
của các ứng dụng giọng nói tự động cho các ngôn ngữ thấp tài
nguyên, góp phần nâng cao trải nghiệm người dùng và giúp cho
các ngôn ngữ này được sử dụng rộng rãi hơn trong các ứng
dụng công nghệ.
Nghiên cứu này tập trung vào phương pháp tăng cường dữ liệu để giải quyết các bộ dữ liệu nhỏ và giúp mạng học sâu có khả năng phủ sóng tốt hơn trong nhiệm vụ ASR. Kết quả thực nghiệm trên các cấu hình khác nhau của bộ dữ liệu VIVOS và hai biến thể của kiến trúc mạng Conformer cho thấy phương pháp được đề xuất của chúng tôi có sự cải thiện đáng kể.
Thông qua các phương pháp làm nhiễu dữ liệu trong
Spectrogram nhóm nghiên cứu đạt được một số
kết quả trên một số nguồn dữ liệu ít tài nguyên như Tiếng
Việt, kết quả nghiên cứu cũng đã được published trên báo
NICS (Conference: 2022 9th NAFOSTED
Conference on Information and Computer Science), và cũng
đã tham đự cuộc thi VLSP2022
Link thông tin: https://www.researchgate.net/publication/364305576_Improving_Automatic_Speech_Recognition_for_Low-Resource_Language_by_Data_Augmentation
